Pagina de start
Parteneri
Coordonator si responsabili
Obiective
Rezumat
Ahitectura Grai
Plan de realizare
Contact
Evenimente
Rezultate
English version
|
Rezultatele obtinute
1. Studii si rapoarte de cercetare
Au fost realizate studii si analize asupra stadiului actual in urmatoarele domenii: arhitecturi, aplicatii si servicii grid (UTI-CE); servicii grid axate pe probleme de inginerie tehnologica si logistica (UTI-CE); aplicatii grid pentru epidemiologie si bioinginerie (UMF-B); aplicatii grid si e-learning pentru agricultura (USAMV-H); aplicatii GMES, arhitecturi si aplicatii grid axate pe probleme procese economice si sociale (AR-IIT).
Au fost realizate rapoarte de cercetare in care sunt prezentate in detaliu toate rezultatele activitatii echipelor de cercetare partenere in proiectul GRAI.
2. Platforma grid GRAI
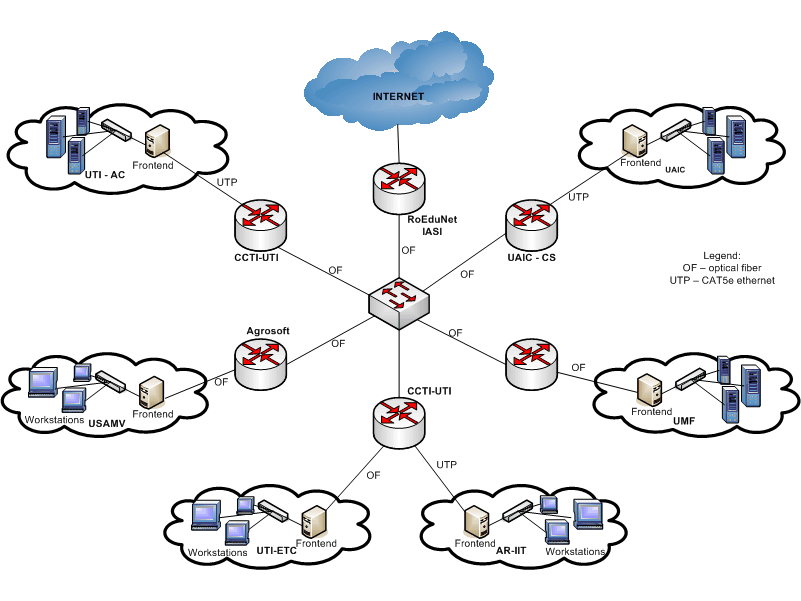
Gridul GRAI este organizat pe 4 niveluri: nivelul resurselor de calcul, nivelul serviciilor, nivelul aplicatiilor, nivelul de informare.
Pentru instalarea nodurilor retelei a fost ales sistemul de operare Linux, o versiune compatibila cu RedHat Enterprise Linux. Pentru instalarea automata a nodurilor din clustere a fost ales RocksCluster datorita automatizarii complete a procesului de instalare. Imaginile cu sistemul de operare sunt cele de la CentOS dar sistemul este functional atat pe RedHat EnterpriseLinux cat si cu ScientificLinux sau Fedora Core. Instalarea sistemului de operare pe frontend-urile din locatiile partenere s-a facut de pe serverul central localizat la conducatorul de proiect, dar in cazuri extreme se poate opta si pentru instalarea de pe CD/DVD. Pachetul Grid Roll ce furnizeaza middleware-ul Globus Toolkit 4 (GT4) in distributia RocksCluster, a fost instalat pe sistemele frontend si pe noduri impreuna cu pachetele SGE Roll si Condor Roll precum si dependentele ( Java JDK, Apache Ant, Junit, PostgreSQL). Pentru interconectarea si distribuirea job-urilor intre clustere se poate folosi: Condor, SGE sau PBS.
Structura unui nod
3. Produse software
Universitatea Tehnica "Gh. Asachi" Iasi (UTI-CE)
Conducatorul de proiect UTI-CE a avut sarcini multiple in cadrul proiectului. Una dintre acestea a vizat dezvoltarea de servicii grid de baza (suport pentru aplicatii) si orientate pe probleme. Astfel, in domeniul data-mining a fost definit si implementat un serviciu de analiza a datelor, in zona vizualizarii datelor a fost realizat un serviciu complex bazat pe algoritmi de randare paralela iar pe directia agentilor mobili si calculului evolutiv a fost dezvoltat un serviciu dedicat problemelor de optimizare. De asemenea, a fost realizat un serviciu de modelare cu retele neuro-fuzzy CML a unor procese populationale, au fost definite si implementate servicii si aplicatii grid in domeniul ingineriei tehnologica si logisticii.
Facultatea de automatica si calculatoare:
a) Serviciu de analiza a datelor
Serviciul Grid pentru analiza datelor oferit de GRAI are o structura bazata pe 2 componente. Prima componenta are rolul dedicat de analiza efectiva a datelor si a fost dezvoltata in C++, pentru paralelizare fiind folosit standardul MPI 2.0. A doua componenta are rolul de a incapsula modulele de analiza sub forma a 2 servicii Grid dedicate.
a1) Componenta de analiza a datelor:
Aceasta componenta este destinata analizei seturilor frecvente intr-o multime de tranzactii. Au fost implementate versiunile paralele pentru 2 dintre cei mai cunoscuti algoritmi: algoritmul Hash Partitioned Apriori (HPA) si, respectiv, o paralelizare proprie a algoritmului FP-Growth (Frequent Pattern Growth).
Hash Partitioned Apriori Modulul HPA al serviciului Grid abordeaza problema determinarii tuturor seturilor frecvente intr-o multime de tranzactii, considerand ca atat itemii cat si tranzactiile sunt reprezentate sub forma binara. Modulul lucreaza direct peste bazele de date, fiind dependent de existenta unei baze de date MySQL si de biblioteca mysql++. O observatie importanta este aceea ca implementarea elimina complet comunicatiile dintre nodurile de procesare. In acest sens, la sfarsitul fiecarei etape caracteristice algoritmului fiecare nod de procesare va insera in baza de date rezultat multimea de seturi frecvente de itemi.
FP-Growth
Acest modul adreseaza de asemenea problema determinarii tuturor seturilor frecvente de itemi intr-o baza de date tinta, dar spre deosebire de modulul anterior, nu necesita existenta unei baze de date suport. Pentru acest modul, baza de date supusa analizei trebuie transmisa sub forma unui fisier text. Un alt aspect important este acela ca itemii sunt reprezentati prin index numeric. Din acest punct de vedere, pentru o tranzactie trebuie precizat numarul de itemi inclusi si apoi indecsii numerici ai itemilor inclusi in tranzactia in cauza. Modulul genereaza un fisier rezultat ce contine itemii frecventi, sortati descrescator din punct de vedere al suportului, precum si seturile de itemi de dimensiune cel putin 2 rezultate in urma. In plus, in aceasta etapa a fost inserat un modul ce se ocupa strict de determinarea itemilor frecventi intr-o multime de tranzactii. Acest modul a fost, de asemenea, dezvoltat in C++, folosindu-se standardul MPI 2.0 pentru paralelizare. Rolul acestui modul este de a pregati un set de tranzatii si, respectiv, un set de itemi pentru descoperirea seturilor frecvente de itemi si pentru alte metode de analiza, in afara celor descrise anterior.
2) Componenta de incapsulare a modulelor de analiza:
Aceasta componenta are la baza o arhitectura de tip FactoryService/InstanceService si este reponsabila de incapsularea in cadrul a 2 servicii Grid a modulelor prezentate mai sus; primul serviciu incapsuleaza modulele de analiza ce implementeaza HPA si, respectiv, Parallel FP-Growth, iar al doilea serviciu are rolul de a oferi suport pentru preprocesarea itemilor si, respectiv, a tranzactiilor in vederea utilizarii altor algoritmi de analiza fata de cei deja implementati. Scenariul general de funtionare este descris in continuare: Clientul autorizat poate initiaza o cerere pentru o resursa noua (cu seminificatia inceperii unei noi analize) sau se poate conecta direct pe o resursa deja existenta (prin intermediul serviciului de instanta) in scopul consultarii stadiului actual al unei analize in desfasurare sau in scopul consultarii unor rezultate ale unei analize deja incheiate; in cazul in care clientul autorizat doreste inceperea unei analize noi, se va initializa o resursa noua, pentru care se intoarce clientului o referinta EPR (EndpointReference). Aceasta referinta va fi salvata pe statia de lucru a clientului, apoi acesta se va conecta, prin intermediul serviciului instanta la resursa nou creata; prin intermediul serviciului instanta se vor specifica seterile specifice analizei dorite si modalitatea de logare a aplicatiei; serviciul instanta parcurge urmatorii pasi: verifica existenta modulului de analiza solicitat; scrie fisierele de configurare ale clientului in locatii accesibile modulului de analiza solicitat; preia de la client scripturile RSL WS-GRAM (scripturi ce au rolul de a descrie funtionalitatea modulului de analiza solicitat si, de asemenea, de a specifica necesarul de resurse Grid) si credential-urile de tip proxy pentru autentifcare, apoi va incerca lansarea in rulare printr-un apel catre ManagedJobFactoryService clientul poate monitoriza apoi statusul jobului curent sau al altor job-uri trimise anterior spre rulare.
b) Serviciu de vizualizare
Sistemul de vizualizare dezvoltat are ca scop implementarea in grid-ul GRAI a unor algoritmi de randare paralela necesari vizualizarii unor seturi de date de mari dimensiuni. Sistemul este bazat pe un framework de vizualizare ce permite unui utilizator autorizat sa acceseze resursele grid-ului GRAI in vederea vizualizarii datelor. Framework-ul propus este bazat pe trei componente pentru care pot exista instante multiple in cadrul aceleiasi organizatii virtuale: componenta client, componenta serviciu, componenta nod de lucru. Utilizatorul interactioneaza cu sistemul de vizualizare prin intermediul unei aplicatii client ce foloseste OpenGL pentru vizualizarea datelor. Aplicatia client contacteaza serviciul de randare responsabil cu divizarea task-urilor de randare corespunzatoare cererii provenite de la client si executarea lor pe nodurile de lucru disponibile. Pentru ca mai multe instante ale componentei client sa poata interactiona cu serviciul de randare, acesta din urma trebuie sa fie capabil sa administreze instante distincte ale resurselor corespunzatoare fiecarei componente client. Pentru aceasta, serviciul de randare este creat folosind un sablon de proiectare cunoscut sub numele de factory /instance pattern. in acest pattern, crearea resurselor nu se poate face in mod direct, ci prin intermediul unui serviciu fabrica (factory), astfel incat pentru componenta serviciu pot exista instante multiple, fiecare asociata unei instante a componentei client. Sistemul de vizualizare dezvoltat se bazeaza pe o arhitectura client - serviciu - nod de lucru in care managementul si executia task-urilor de randare revin in totalitate componentei serviciu, fiind astfel transparenta pentru client. Singura cerinta impusa pentru aplicatia client este ca aceasta sa ruleze pe un nod de calcul inregistrat in sistemul grid, iar utilizatorul sa fie legitimat prin intermediul unui proxy grid sa acceseze serviciile puse la dispozitie. Interactiunea dintre componenta serviciu si componenta nod de lucru se realizeaza pe baza acestei legitimari, autorizarea clientului fiind delegata instantei serviciului pentru ca acesta sa fie capabil sa ruleze job-uri pe nodurile de lucru si acestea sa poata returna rezultatele obtinute serviciului, conform cerintelor de securitate impuse. Componenta client este o aplicatie Java ce foloseste biblioteca OpenGL prin intermediul unei librarii wrapper (JOGL) pentru a permite utilizatorului sa interactioneze cu sistemul de vizualizare si sa exploreze rezultatele vizualizarii. Interactiunea aplicatiei client cu sistemul de vizualizare presupune specificarea a doua tipuri de parametri: 1) de executie a sistemului de vizualizare pe grid si 2) de vizualizare Parametrii de executie a sistemului de vizualizare sunt specificati prin intermediul interfetei grafice a aplicatiei client. Componentele nod de lucru disponibile sunt determinate interactiv de catre aplicatie, utilizatorul putand specifica pe care din aceste componente se vor executa job-urile de randare. Parametrii de vizualizare sunt dinamici, acestia fiind determinati de aplicatia client in urma interactiunii utilizatorului cu fereastra OpenGL. Orice modificare a parametrilor de vizualizare determina o noua executie a componentelor job-urilor de randare pe nodurile specificate. Framework-ul de vizualizare propus poate fi extins pentru a implementa diverse scheme de vizualizare bazate pe randarea paralela si in general poate oferi functionalitatea necesara implementarii oricarui algoritm paralel in care este necesara existenta unui proces master care sa coordoneze executia task-urilor de catre nodurile de lucru si sa sintetizeze rezultatele produse, iar pentru nodurile de lucru nu exista cerinte de inter-comunicare. De fapt, arhitectura sistemului a fost astfel proiectata pentru a permite crearea unui framework generic care sa simplifice procesul de dezvoltare de noi servicii grid. Astfel, sistemul dezvoltat poate fi usor transformat intr-un serviciu grid configurabil care sa puna la dispozitie un model de programare de nivel inalt prin care sa se elimine complexitatea tratarii serviciilor web si a tehnologiilor grid, atragand astfel mai multi utilizatori neexperimentati catre exploatarea resurselor sistemelor grid.
c) Serviciu grid bazat pe agenti mobili
Serviciul grid bazat pe agenti mobili (clumake_service) pune la dispozitia utilizatorilor o interfata de conectare la resursele gridului GRAI si implicit la platforma de agenti mobili CluMake (Cluster Make). Prin intermediul modulului GA (Genetic Algorithms) si al claselor, interfetelor si modelelor puse la dispozitie, utilizatorii pot dezvolta si rula in cadrul gridului GRAI algoritmi genetici pentru diverse tipuri de probleme, beneficiind de toate caracteristicile unui grid cum ar fi printre altele echilibrarea incarcarilor intre noduri, rularea transparenta a taskurilor, optiuni de securitate a datelor. CluMake este o platforma robusta de agenti mobili peste care utilizatorul are posibilitatea construirii unui cluster virtual ale carui noduri indeplinesc anumite restrictii specificate (procesor, memorie, servicii etc.) cat si posibilitatea de rulare a serviciilor existente. Sistemul este implementat sub forma unui framework care face posibila construirea unui astfel de cluster cat si rularea serviciilor existente in cadrul acestuia. Acest framework este bazat pe agenti mobili si stationari dezvoltati sub limbajul de programare Java, oferind suportul de baza necesar pentru dezvoltarea oricarui tip de agenti: agenti de load balancing, agenti de comunicatii, agenti mobili si stationari care pot incapsula servicii, agenti de snapshot global, agenti inteligenti etc. Reteaua la care utilizatorul are acces este compusa dintr-un set de POP-uri (puncte de prezenta). Fiecare POP reprezinta un server care ofera utilizatorului un punct de acces in retea. Prin urmare, singurul lucru pe care utilizatorul trebuie sa il cunoasca la un moment dat este numele celui mai apropiat POP. POP-ul reprezinta un punct de intrare in sistem pentru utilizator. Odata specificat, un agent mobil creat de catre aplicatia client va calatori catre acest POP. Fiecare POP din retea mentine o lista cu cele mai apropiate legaturi (host-uri). Odata ajuns la POP, agentul mobil initiaza o sesiune de comunicare cu acesta in cadrul careia va primi lista de legaturi mai sus mentionata. Dupa primirea listei de legaturi, agentul mobil isi poate incepe calatoria in retea catre oricare dintre nodurile specificate in cadrul acesteia. Flexibilitatea API a framework-ului da posibilitatea utilizatorului sa specifice care este numarul maxim de hop-uri peste care poate calatori agentul mobil pentru a cauta noduri in retea care satisfac restrictiile si serviciile specificate. Platforma CluMake poate fi conectata cu diverse modulul de calcul. in acest sens, conducatorul de proiect a realizat un modul de calcul bazat pe algoritmi genetici, orientat pe probleme de optimizare. Au fost dezvoltate clase speciale de agenti GA care ruleaza in cadrul platformei CluMake si care folosesc mesaje sincrone pentru calcularea solutiei pentru o gama larga de probleme care pot fi rezolvate pe baza algoritmilor genetici. Pentru calcularea solutiilor, agentii GA folosesc modulul de optimizare bazat pe algoritmi genetici. Serviciul grid implementat ofera o interfata generica prin care utilizatorul poate trimite o cerere de rezolvare cu ajutorul algoritmilor genetici a unui anumit tip de problema. in cadrul testelor efectuate, s-au dezvoltat algoritmi genetici pentru urmatoarele probleme: Knapsack, Rastrigin, TSP, Sphere, Arbori Steiner minimali.
Facultatea de Electronica si Telecomunicatii:
Serviciu de modelare cu retele neuro-fuzzy CML a unor procese populationale Scop: Implementarea distribuita a unui set de retele (latici) de functii cuplate cu celule de tip sistem fuzzy pentru modelarea unor procese populationale. Un alt mod de a vedea aceste sisteme este cu sisteme neuro-fuzzy de tip CML (coupled map lattices).Se recomanda simularea unor populatii mari prin latici 100-1000 celule, care evolueaza un timp indelungat 10000 pasi de timp (epoci). Tipuri de modele populationale: 1.Modele populationale neuro-fuzzy, in varianta Sugeno, cu diverse tipuri de structuri, vecinatati, celule, conditii initiale si modalitati de agregare, intre care utilizatorul poate sa aleaga.
2.Modele populationale neuro-fuzzy, in varianta Mamdani, cu diverse tipuri de vecinatati.
3.Modele complexe, de sisteme combinate Sugeno si logistice inseriate, etc.
4.Modele in care se ia in considerare zgomotiul de transmisie (sau, echivalent, fluctuatiile locale ale sistemului, modelate prin fluctuatoii de intrare, de tip zgomot.)
5.Modele adaptive Sugeno.
Parametrii retelei:
A.Tipul de vecinatate
B.Numarul de elemente pe o linie
C.Numarul de cicli (echivalent, numarul de linii)
D.Tipul de retea: planara sau cilindrica
E.Modul de agregare al intrarii:
agregare determinista liniara neponderata
agregare determinista liniara ponderata agregare determinista neliniara de tip sigmoidal
agregare ne-determinista, fuzzy
cu vecinatate simetrica ,
cu vecinatate asimetrica etc.
Versiunile puse la dispozitie sunt, in principal: sisteme fuzzy ficate cu functii de apartenenta Gauss, avand parametrii functiilor Gauss de intrare si sigletonii de iesire prefixati. Se pot utiliza sisteme SISO (Single-input single-output), sau DISO (two-input single-output systems). Graful retelei este directionat, nu este strongly connected, dar este slab conectat (in sensul ca graful nedirectioat corespunzator este total conectat). Oricare dintre noduri poate fi afectat de un zgomot uniform, conform unei legi de distributie (interval de valori ale zgomotului) care poate fi precizat de catre utilizator.
Recomandari:
Distribuirea calculului pentru modelele populationale neuro-fuzzy de tip CML bazate pe modele Sugeno se justifica daca numarul de celule (indivizi) din proces este mai mare de cateva sute si daca numarul de pasi de rulare este sensibil mai mare de 1000. Avantaje sensibile se obtin numai daca numarul de celule este de ordinul miilor sau mai mare, iar numarul de pasi de rulare este de ordinul 10’000 sau mai mare. in aceste cazuri insa, fisierul complet de date rezulta foarte mare (GB) si, functie de problema practica, este preferabil fie ca si datele sa ramana distribuite, fie ca numai rezultatele finale, dupa o perioada de evolutie a retelei, sa fie retinute.
Scoala de Studii Doctorale, Facultatea de Automatica si Calculatoare
Grupul de obiective alocat colectivului de cercetare de la scoala de Studii Doctorale, Facultatea de Automatica si Calculatoare, a Universitatii Tehnice "Gh. Asachi" a abordat dezvoltarea de aplicatii din domeniul serviciilor grid axate pe probleme de inginerie tehnologica si logistica. Grupul de probleme tinta a constat in probleme de inginerie de proiectare VLSI referitoare la partitionarea circuitelor in vederea testarii, optimizarea diagramelor de decizie binare ordonate (OBDD), precum si probleme din domeniul managemntului operational cum ar fi clustering distribuit si predictia evolutiei clusterelor dependente de timp, optimizarea alocarii resurselor si probleme de rutare. Au fost realizate studii cuprinzatoare asupra cerintelor specifice problematicii abordate la nivel de proiectare de algoritmi, implementare si exploatare, care au avut ca efect decizii de modelare, solutii algoritmice hibride cu un paralelism potential de mare granularitate, solutiii recomandate de implementare si modalitati de exploatare eficienta cu avantaje practice reale. in domeniul fiecarei probleme au fost identificate realizarile existente si oportunitatile referitoare la implemnatarea paralela/distribuita. Aceste demersuri au avut ca rezultat specificatii detaliate de proiectare a unor servicii corespunzatoare grid de nivel II, orientate pe problemele din inginerie tehnologica si logistica mentionate. Au fost in continuare codificate si testate serviciile respective, au fost realizate ameliorari ale modelelor utilizate si au fost descoperite modalitati de exploarea intensiva a resurselor folosind solutii algoritmice hibrizi. Continuand implementarea si testarea serviciilor repartizate pentru expunere pe gridul GRAI in vederea cresterii functionalitatii acestora, au fost proiectate noi tipuri de algoritmi genetici segregativi pentru problemele de proiectare VLSI si noi algoritmi hibrizi rezultati prin grefarea in special a unor metode exacte de tip ramificare si marginire pe algoritmici genetici cu reprezentari embrionare. Ca urmare a evaluarilor experimentale complexe au fost elaborati algoritmi genetici segregativi care combina cautarea tabu si memoriile asociative pentru explorarea sistematica o populatiilor multiple de solutii pentru problemele abordate si au fost obtinute extensii pentr alte tipuri de probleme. in consens cu exploatarea resurselor de calcul distribuite, au fost obtinute versiuni segregative pentru algoritmi genetici in care gestiunea cautarii se face prin exploatarea similitudinii existente intre imaginile solutiilor intr-un spatiu de caracteristici. in acest sens, se raporteaza dezvoltari de algoritmi genetici segregativi distribuiti pentru probleme de optimizare fara restrictii in Rn, probleme de partitionare districtuala, probleme de alocare a depanatorilor precum si probleme de echilibrare pentru procesarea de tip 'pipeline'. Cercetarile efectuate au fost extinse si catre proiectarea unor instrumente de vizualizare a evolutiei explorarii unor populatii distribuite de solutii in care subpupulatiile au o dinamica proprie de aparitie, dezvoltare, exploatare, comunicare si tezaurizare. Pe parcursul cercetarii au fost elaborate referate, lucrari si capitole in 5 teme aferente unor teze de doctorat, dintre care trei sunt in stadiul final. Cercatarile au condus la formularea a doua noi teme de cercetare pentru doctorat.
Universitatea "Al.I. Cuza" (UAIC-I)
Sarcina partenerului UAIC-I a constat in analiza, definirea specificatiilor, implementarea si testarea unor servicii grid pentru rezolvarea de probleme din diferite domenii ale informaticii, precum si realizarea unor aplicatii care sa utilizeze aceste servicii. Domeniile abordate se inscriu intr-o gama larga: web semantic, optimizare combinatoriala, rezolvarea problemelor de programare bazata pe constrangeri (CSP), metode ale calculului evolutiv, procesarea limbajului natural, e-learning. in continuare sunt descrise serviciile realizate.
a) Web semantic Aplicatiile dezvoltate in cadrul acestui domeniu se refera la modalitatile de implementare a serviciilor Grid pentru managementul inteligent al resurselor. Prima aplicatie are in vedere monitorizarea resurselor din nodurile gridului si a fost realizata utilizand o arhitectura orientata pe servicii. Astfel, nivelul de procesare (business logic) este incorporat intr-un serviciu Web. in spiritul conceptelor din grid computing si servicii Web, aplicatia utilizeaza o combinatie de tehnologii diferite care interactioneaza in permanenta: Java, .NET, limbajele HTML si SVG. A doua aplicatie Web este de tip mashup si se aliniaza problematicilor Web-ului social. Folosind API-uri publice puse la dispozitie de Google si recurgand la servicii grid, aplicatia ofera utilizatorului un instrument de creare si acces la harti adnotate. Datele privitoare la harti pot fi stocate ca si triple RDF in cadrul sistemului grid considerat.
b) Programare bazata pe constrangeri
in domeniul programarii bazate pe constrangeri au fost urmarite doua obiective. Pe de o parte a fost propusa o abordare hibrida in rezolvarea problemelor de optimizare combinatoriala, utilizand programarea bazata pe constrangeri si calculul evolutiv. Dupa cum s-a dovedit, incorporarea unor euristici in cadrul algoritmilor evolutivi poate imbunatati rezultatele cautarii. Serviciul dezvoltat se axeaza pe rezolvarea problemelor de tipul MaxCSP. Algoritmul de inferenta folosit este Mini-Bucket Elimination, versiunea aproximata a algoritmului de inferenta directionala Bucket-Elimination, care elimina o serie de dezavantaje ale acestuia. Testele efectuate au demonstrat eficienta abordarii hibride, profitand si de puterea de calcul oferita de grid. Pe de alta parte, a fost realizat un serviciu grid cu functionalitatea unui solver, numit OminCS, dedicat rezolvarii problemelor de satisfacere a constrangerilor. Studiile de caz au aratat ca utilizarea arhitecturilor de tip grid este foarte eficienta in cazul problemelor de satisfacere a constrangerilor, care sunt mari consumatoare de resurse de calcul.
c) Colorarea grafurilor
O multitudine de probleme din viata reala pot fi modelate si rezolvate prin reducere la problema colorarii grafurilor, care astfel este in mod particular importanta. Aplicatia dezvoltata, orientata spre rezolvarea problemelor de colorare a grafurilor, este construita pe o arhitectura client-server. Serviciul grid, care joaca rolul serverului, implementeaza o serie de tehnici de colorare, profitand de puterea de calcul oferita de grid, iar clientii se folosesc de acesta pentru rezolvarea problemelor reale. Pentru reprezentarea grafurilor este folosit formatul DIMACS, dezvoltat la Rutgers University. Datorita specificului problemei, utilizatorul uman intervine direct in mersul aplicatiei, atat in alegerea tehnicii de colorare utilizate, cat si in evaluarea validitatii solutiilor otinute si eliminarea celor considerate gresite.
d) Procesarea limbajului natural
Problema abordata se refera la analiza si recunoasterea inferentelor textuale intre texte. Arhitectura aleasa pentru aplicatie este de tipul peer-to-peer. Datorita complexitatii problemei, au fost dezvoltate o serie de servicii lingvistice. Pe de o parte, serviciile lingivstice de baza sunt urmatoarele:
- Serviciul de lematizare - folosit pentru gasirea lemei unui cuvant. Acestui serviciu i se transmite ca intrare un cuvant si dupa cautarea in resursa cu toate formele flexionate ale cuvintelor, intoarce lema cuvantului (in caz de succes) sau cuvantul initial (in caz de insuces).
- Serviciul WordNet - folosit pentru gasirea sinonimelor unui cuvant. Acestui serviciu i se transmite ca intrare un cuvant, substantiv sau adjectiv, iar dupa cautarea in WordNet-ul extins returneaza o lista de sinonime pentru cuvantul initial (care poate fi si goala, in caz de insucces).
- Serviciul Dirt - similar cu serviciul WordNet, utilizeaza baza de date DIRT pentru gasirea sinonimelor pentru verbele englezesti.
- Serviciul semnificatie acronim - folosit pentru a identifica semnificatia unui acronim. Pentru un cuvant transmis ca intrare, acest serviciu cauta in resursa de acronime semnificatia cuvantului initial, care este intoarsa in caz de succes. in caz de insucces se intoarce un cuvant vid.
- Serviciul pentru folosirea cunoasterii suplimentare - folosit pentru a identifica informatii utile extrase de pe Wikipedia. in caz ca nu gaseste informatii utile, este salvat intr-un fisier separat pentru procesari viitoare.
Pe baza serviciilor de baza au fost apoi dezvoltate serviciile lingvistice compuse, care implementeaza algoritmi specifici pentru rezolvarea problemei de determinare a existentei inferentei textuala intre doua texte. Acesti algoritmi nu folosesc limba in care sunt scrise textele si se bazeaza exclusiv pe rezultatele intoarse de serviciile lingvistice de baza. Serviciile lingvistice compuse sunt: - Serviciul de transformare a ipotezei - primeste la intrare o propozitie si intoarce la iesire un vector de vectori, obtinut prin expandarea fiecarui cuvant din ipoteza. Pentru aceasta se folosesc toate serviciile lingvistice de baza: lematizare, WordNet, Dirt, acronim si folosirea cunoasterii suplimentare.
Serviciul de transformare a textului - primeste la intrare o propozitie si intoarce la iesire un vector de vectori, obtinut prin expandarea fiecarui cuvant din text cu ajutorul serviciului de lematizare.
Serviciul de calculare a potrivirii dintre text si ipoteza - primeste la intrare doua multimi de vectori corespunzatoare textului si ipotezei care au fost transformate de serviciile de mai sus. Iesierea este un numar cuprins intre 1 si 100, reprezentand distanta dintre cele doua texte. Daca se obtine o distanta mica, vom deduce ca avem inferenta intre text si ipoteza, iar daca distanta este mare vom deduce ca nu putem infera ipoteza din text.
e) Protein folding
Protein folding reprezinta o problema de optimizare combinatoriala specifica bioinformaticii. Concret, se urmareste determinarea structurii tridimensionale a unei proteine pornind doar de la secventa de aminoacizi, folosind metode de simulare computationala. La fel ca in cazul altor domenii, aplicatia dezvoltata exploateaza potentialul sistemelor de tip Grid, dat fiind necesarul ridicat de resurse de calcul solicitate de catre aplicatiile din domeniul bioinformaticii. in mod specific, protein folding implica rezolvarea unor probleme de optimizare combinatoriala de mare complexitate. Aplicatia este proiectata sub forma client-server, in care serverul primeste de la clienti diferite secvente de aminoacizi, asupra carora se aplica diferiti algoritmi de folding, cum ar fi algoritmi exhaustivi sau algoritmi de tip branch-and-bound
f) Calcul evolutiv
A fost dezvoltat un serviciu grid care furnizeaza un cadru de lucru pentru rezolvarea problemelor cu ajutorul algoritmilor genetici. Pornind de la descrierea componentelor definitorii ale unui algoritm genetic, serviciul instantiaza si rulezaza algoritmul genetic, oferind atat solutia obtinuta, cat si diverse statistici de performanta calculate pe parcursul rularii algoritmului. Implementarea este realizata in limbajul Java si foloseste biblioteca ECJ, dezvoltata in cadrul George Mason University. Experimentele confirma faptul ca, in cazul algoritmilor genetici, sporul de performanta adus de sistemul grid depinde de balansul dintre complexitatea problemei abordate si volumul necesar de comunicatii intre unitatile de calcul.
g) E-learning
Scopul principal avut in vedere a fost utilizarea unei ontologii de domeniu pentru modelarea atat a utilizatorilor, cat si documentelor, precum si utilizarea acestor modele pentru a oferi recomandari personalizate de resurse utilizatorilor. Eforturile s-au concretizat in elaborarea a trei servicii principale:
- User Modeler Service, vizand dezvoltarea unui model utilizator bazat pe standardul IEEE-PAPI care include trei nivele de profil: competente, interese si amprente (competences, interests, fingerprints), exprimate prin intermediul unor constructii ontologice
- Document Modeler Service, vizand dezvoltarea unui model document bazat pe standardul IEEE-LOM care include adnotarile bazate pe ontologia de domeniu asociate fiecarui document
- Recommender Service, care furnizeaza recomandari personalizate de documente utilizatorilor pe baza profilului lor
Universitatea de Medicina si Farmacie "Gr.T.Popa" Iasi (UMF-B) Aplicatiile grid realizate de colectivul UMF-B se refera in principla la un pachet de doua aplicatii, prima din domeniul medical (epidimiologie) iar a doua din domeniul bioingineriei (aliniere de secvente genomice, cu aplicatii in bioinformatica). Cele doua aplicatii sunt distincte in ceea ce priveste partea algoritmica si de interes a utilizatorului final, si din acest motiv s-au coneceput doua sub-aplicatii distincte, la nivel de utilizator care sunt accesibile la GRID ca aplicatii instalate end-user. Utilizatorul se autentifica pentru a avea acces la cele doua servicii denumite BioGridEpidemiology Service si BioGridSeqAlign Service folosind precedura comuna de conectare prezenta in toate serviciile grid utilizate de toti partenerii. Utilizatorul logat la cele doua servicii va avea acces numai la cele doua servicii. Daca un utilizator de la UMF-B doreste accesarea unui serviciu implementat de alt partener trebuie sa se logheze cu user-ul si parola alocate acelui serviciu, pentru a avea acces la resursele respective. Utilizatorul trebuie sa aiba instalate cele doua aplicatii pe statia de pe care doreste a se lucra si conecta la serviciul de grid, identificat in cadrul grid-ului prin IP-ul corespunzator. Aplicatiile au fost implementate in Java, utilizand la maximum caracterul de Open Source al compilatorului de Java care a fost utilizat, ECLIPSE, cu plug-in pentru proiectarea interfetei grafice Jigloo, care este de asemenea free. Modelul epidimiologic pus la dispozitia utilizatorilor ca servicii grid permite simularea unui model epidimiologic compartimental bazat pe ecuatii diferentiale, si anume SIR (S - susceptibil, I - infectios, R - recuperat, E - expus, M- maternal.) cu varianta stochastica. Literele reprezinta numarul de persoane care se afla in fiecare compartiment, si se definesc ca functii de timp care au respectivele valori la momentul t (cuante discrete de timp): S(t), I(t), R(t), E(t) si respectiv M(t). in diferite variante de paralelizare (SIR, SIRS, SEIR, si SEIR spatial) s-au utilizat modele au un caracter deterministic. Paralelizarea abordata a fost pe doua directii: paralelizarea ecuatiilor diferentiale care s-a dovedit a avea un castig minimal in ceea ce priveste rularea in paralel pe 2, 4, si respectiv 8 noduri si abordarea paralelismului prin rularea fiecarei aplicatii create de un utilizator individual pe un procesor alocat fiecarui task. La aceasta a doua abordare, cu maximum 10 utilizatori (o grupa de bioinginerie), castigul ca timp a reprezentat o imbunatatire substantiala. Utilizatorul are posibilitate de a opta intre aceste doua variante, cu anumite limitari. Utilizatorul poate alege in primul caz 2, 4 sau 8 procesoare, pentru fiecare fiind implementata o varianta paralela a modelului SIR. in al doilea caz este o optiune simpla, utilizatorul ruland task-ul pe un procesor din cluste in mode complet transparent. Transferul datelor in si de la grid se face pe 2 fisiere la transmiterea task-ului (fisiere in format ASCII care contin parametrii de rulare al modelului SIR, parametrii alesi de utilizator si desigur perioada de simulare) iar primirea rezultatelor simularii se face printr-un fisier ASCII formatat, citibil din EXCEL, care are 4 coloane ce contin pentru fiecare cuanta de timp pe linie N(ti), S(ti), I(ti), si R(ti). Valorile sunt afisate intr-o fereastra si se poate opta si pentru varianta grafica a evolutiei compartimentului I(t). Rezultatele pot fi transferate prin operatiuni de cut-paste in instrumente de vizualizare pentru prelucrari ulterioare. A doua aplicatie se refera la liniere globala secvente genomice folosind algoritmul Needleman-Wunch.. O comanda de aliniere de exemplu a doua secvente, identificate in fisierele ASCII ca A.txt si B.txt, raspunsul venind sub forma a trei linii de caractere: primul rind reprezinta prima secventa, al doilea rand caracterele de aliniere si al treilea rand a doua secventa. S-a introdus o limitare a lungimii secventei genomice pentru a putea fi utila la citire in aspecte didactice si de asemeni la matricea de substitutie care este una singura, des utilizata in aplicatii, BLOSUM62. Tabela cunoscuta in literatura descrie substitutiile observate in lanturi de peptide aliniate (C, S, T, P, A, G, N, D, E, Q, H, R, K, M, I, L, V, F, Z, W) . Algoritmul Needleman-Wunch (NW) utilizeaza programarea dinamica pentru rezolvarea problemei intr-o zona de memorie. Toate perechile de rezduuri (baze ADN sau protein-amino-acizi) sunt reprezentate intr-o arie bidimensionala. Secventele sunt scrise incepind din coltul stinga-sus catre dreapta si in jos. Gap-urile sunt completate cu scoruri de penalizare, in cazul nostru -5. Paralelismul este implementat prin exploatarea constructiei matricii de cost in calcul inainte. in medie, timpul de calcul se reduce de la O(MxN) la O(M+N). Algoritmul utilizat este una din variantele mai putin cunoscute in literatura, dar care are avantajul posibilitatii de implemenentare mai rapide in cazul nostru. Celelalte etape ale algoritmului, repectiv backward raman secventiale si sunt alocate unui singur procesor, cel care a fost initializat pentru task-ul respectiv. Pentru ambele servicii, au fost efectuate teste pentru pentru diferite valori aler numarului de procesoare alocate in varianta paralela si pentru numere diferite de utilizatori in cazul alocarii unui singur task-utilizator unui procesor. Rezultatele au aratat in medie imbunatatiri semnificative in cazul unui numar mare de utilizatori si in general imbuntatiri foarte mici in cazul unui numar foarte mic de utilizatori. A fost si o exceptie unde in anumite cazuri timpul de rulare al algoritmului de modelare epidimiologica (un singur utilizator si o paralelizare la nivel de necunoscuta in cadrul ecuatiilor), timpul pentru varianta paralela sa fie mai mare cu pina la 20% fata de varianta seriale. Aceste variante ineficiente au fost eliminate din produsul final, constituindu-se doar in observatii si remarci. Interfetele grafice implementate in Java sunt minimale, oferind informatiile necesare in maniera prietenoasa si evitand supraincarcare cu clase grafice. Scopul acestei abordari a fost pe de o parte realizarea unui uneor modele simple si usor accesibile in aplicatii de tip tutorial si pe de alta parte reducerea constrangerilor in dezvoltari ulterioare datorita unei interfete complexe care s-ar putea sa necesite modificari substantiale noilor scopuri.
Universitatea de stiinte Agricole si Medicina Veterinara "Ion Ionescu de la Brad" Iasi (USAMV-H)
Partenerul USAMV-H si-a propus dezvoltarea de servicii grid de nivel II, orientate pe problema. Au fost alese domenii care privesc cele doua laturi ale stiintelor agricole: cercetarea stiintifica si procesul didactic. In ambele cazuri , a fost vizata demararea unui proces de integrare intr-un cadru de colaborare modern, multi-universitar si multi-disciplinar, care sa aduca si avantajul accesului la un sistem de resurse computationale de mare performanta. in domeniul cercetarii stiintifice inter-disciplinare s-au investigat posibilitatile de a introduce sisteme de asistare a deciziei in activitatea de exploatare durabila a resurcelor de sol. S-a ales, ca subiect pilot, realizarea unui sistem de asistare a deciziei pentru infiintare de sere si solarii. Pentru cel de-al doilea, s-a hotarat introducerea tehnologiilor e-learning pentru dezvoltarea unor aplicatii orientate catre domenii didactice care, in prezent, sufera de o receptare mai dificila din partea studentilor. Subiectul pilot a fost dezvoltarea unei aplicatii e-learning pentru cursul de Agrometeorologie a) Sistem de asistare a deciziei pentru infiintare de sere si solarii Un element esential in lansarea unui proiect de construire unei sere este elaborarea unui studiu pedologic care stabileste pretabilitatea terenului pentru acest scop. Studiul pedologic comporta o etapa de teren, o etapa de laborator si o etapa de prelucrare a datelor. in etapa de teren se fac observatii asupra geologiei, litologiei, hidrografiei, morfologiei si asupra altor caracteristici ale solului. Se fac, de asemenea, masuratori climatice. in faza de laborator se efectueaza analize fizico-chimice asupra unor mostre de sol. Pentru evaluarea diferitelor proprietati ale solului, datele din teren si rezultatele analizelor de laborator trebuie incadrate in clasele de pretabilitate ale solului pentru sere. Acestea sunt definite și consemnate oficial. in scopul incadrarii, decidentul are la dispozitie tabele si recomandari si alte elemente de documentatie tehnica dar, din cauza cantitatii mari de date, automatizarea software acestui proces ar aduce avantaje evidente. in acest punct intervine sistemul de asistare a deciziei (Decision Support System - DSS). Sistemul primeste la intrare datele masurate in teren si rezultatele analizelor de laborator. La iesire, furnizeaza un raport care a fost imbogatit, pas cu pas, pe parcursul prelucrarii datelor, cu concluzii partiale privind pretabilitatea solului din diferite puncte de vedere: textura, volum edafic, salinizare, alcalizare, etc. in finalul raportului se emite o concluzie globala asupra pretabilitatii solului. Sistemul utilizeaza o baza de date care stocheaza in tabele clasificarea oficiala a solurilor si recomandarile corespunzatoare acestei clasificari. El este conceput astfel incat sa permita adaugarea de noi tabele in structura bazei de date sau modificarea celor existent, atunci cand acest lucru devine necesar.
Ca serviciu Grid, sistemul se incadreaza in categoria Collaborative Business Grid. Scopul principal al unui astfel de serviciu este sa permita o partajare a resurselor, gestionata si realizata in conditii de siguranta, la un nivel trans-organizational. Serviciile Grid de acest tip se integreaza intr-un sistem web. Sistemul are trei categorii de componente: - date experimentale de intrare,
- indicatori standard si proprietati ale solului,
- algoritmi de prelucrare a datelor si pentru emiterea de concluzii privind pretabilitatea solului.
Interfata cu utilizatorul este conceputa ca o pagina web cu trei sectiuni: Nomenclatoare, Date experiment si Rezultate.
Sectiunea Nomenclatoare este utilizata la imbogatirea si actualizarea bazei de date conform standardelor si documentatiilor oficiale privind pretabilitatea.
Sectiunea Date experiment este utilizata la introducerea datelor rezultate din masuratorile de teren si din analizele de laborator.
Sectiunea Rezultate contine rapoartele emise si concluzia globala privind pretabilitatea solului la infiintarea de sere, precum sugestii de ameliorare pentru aducerea sa in limitele de pretabilitate.
Sistemul permite dezvoltari ulterioare prin rafinarea algoritmilor implementati, precum si prin imbogatirea cu noi module de decizie.
b) Aplicatie e-learning pentru cursul de Agrometeorologie
Este acceptat in prezent faptul ca un mediu de e-learning ofera mijloace, mai diversificate si mai moderne de construire a unui curs mai usor de receptat. Mediul de e-learning permite o abordare complet diferita a structurarii materialului didactic (curs, laborator, aplicatii,teste,examene), moderna, mult mai diversificata in continut si mai atractiva, precum si o schimbare radicala a procesului de invatare, de la cea bazata pe acumularea de cunostinte, la invatarea activa si interactiva, bazata pe o abordare intuitiva si pe formarea activa si interactiva de legaturi intre notiuni, faptele experimentale si datele incluse in baza de date. La o universitate cu profil de stiinte agricole, disciplinele din sfera stiintelor exacte sunt intr-o situatie speciala, atat din punctul de vedere cat si din punctul de vedere al studentului, din cauza departarii domeniilor respective fata de specializari ca: agricultura, horticultura, peisagistica, medicina veterinara, biologie, etc. Din acest motiv, s-a ales ca primele abordari ale tehnologiilor e-learning sa fie indreptate catre realizarea unor cursuri din aceste domenii stiintifice. Primul curs pentru realizat ca aplicatie de e-learning este cel de Agrometeorologie. El se adreseaza studentilor de la specializarile Agricultura, Montanologie si Inginerie Economica in Agricultura, cursuri de zi, precum si celor de la I.D., facultatea de Agricultura Se afla in proces de dezvoltare urmatoarele cursuri: Biofizica - pentru studentii specializarii "Biologie", Facultatea de Agricultura, curs de zi si Facultatea de Zootehnie - I.D.;
Merceologie pentru studentii la master, specializarea « Controlul calitatii produselor agroalimentare » ;
Orientarea in Moodle pentru initierea studentilor acreditati si pentru profesori.
Configurarea blocurilor in pagina unui curs este accesibila si administratorului si profesorului (numai pentru cursul al carui creator este). Blocurile pot fi adaugate, ascunse, sterse si deplasate. Profesorul cu drepturi de editare are la dispozitie un bloc de administrare a cursului cu submeniuri pentru diferite operatii (backup/restore, format, rapoarte, note, activitati etc.). Studentul poate accesa cursul sau cursurile doar dupa ce este inscris de catre profesor. Accesul ii este permis doar la cursurile si activitatile la care a fost inscris. Cursul realizat (Agrometeorologie) este constituit din:
- suportul de baza, accesibil pe capitole, in pagini web separate, prin link-uri din pagina-cuprins;
- material grafic ilustrativ (imagini, filme scurte), accesibile prin link-uri din textul de baza;
- un glosar amanuntit al termenilor de specialitate folositi in suportul de baza, cu acces printr-un link din text reprezentat chiar de termenul respectiv;
-intrebari de diferite tipuri, fara limita de timp, fara notare dar cu depunctare simbolica in cazul unui raspuns incorect, cu posibilitatea de a repeta alegerea in cazul unui raspuns incorect, grupate pe capitole;
-link-uri catre o baza de date meteorologice masurate la statia meteorologica judeteana Iasi si, in special, la statia meteorologica automata a USAMV de la ferma didactica Ezareni;
-link-uri in pagina-cuprins catre paginile Administratiei Nationale de Meteorologie, Organizatiei Meteorologice Mondiale, Sat24.com (pentru imagini din satelit in timp real);
-o rubrica de stiri si anunturi, afisate de catre profesor, accesibile studentilor inscrisi la curs;
-forum de discutii accesibil tuturor: mesajele pot fi postate de catre toti studentii inscrisi la curs;
-calendar de activitati.
Academia Romana, Filiala Iasi, Institutul de Informatica Teoretica (AR-IIT)
a) Serviciu de modelare cu sisteme mari (retele 2D) neuro-fuzzy a unor procese economice si sociale regionale
Scop: Modelarea unor sisteme economice mari ce contin sute de actori pe piata (firme), care aplica strategii de management comune la nivel de grup sau individual (la nivel de firma). S-au propus doua clase de strategii individuale: una bazata pe invidie "comp-benef" (companiile isi compara beneficiile cu cele ale concurentei si copie reactiile competitorilor cu profit mai mare, fapt bine cunoscut in literatura de specialitate ), respectiv strategii de maximizare "max-benef" (firma calculeaza beneficiile obtinute pentru o crestere, scadere, sau mentinere a preturilor de vanzare si ia o decizie care sa ii maximizeze profitul fara a tine cont de celelalte firme).
Fisiere de configurare model economic:
a)Fisierul "firm.in" contine parametrii de rulare ai fiecarui actor de pe piata (pret initial, tip strategie, tip increment, tip descriere seturi fuzzy, valoare increment daca acesta este fix). Tot in acest fisier sunt incluse si informatiile ce descriu activitatea de management a firmei - intarzierile in aflarea preturilor concurentei si conexiunile pe care le are o firma cu firmele concurente de pe piata. Pentru descrierea grupurilor de firme sunt indicate firmele "centrale" care coordoneaza activitatea grupului si eventual functie de strategie influenta pe care o are firma centrala asupra firmelor din grup, pentru a descrie modul in care sunt afectate fluctuatiile de pret de zona in care este amplasata o firma, de concurenta vecinilor, de puterea de cumparare a clientilor in acea zona etc.
b)Fisierele "fuzzy.in1", "fuzzy.in2",..., "fuzzy.inN" folosite la descrierea sistemelor fuzzy SF1 pentru calcul beneficiilor. Contin descrierea fuzzy a conceptelor de "pret" si "beneficiu", precum si a regulilor de inferenta aplicate de o firma in calculul profitului obtinut. S-a considerat ca nu toate firmele din model trebuie sa foloseasca acelasi set de reguli fuzzy, functii apartenenta fuzzy si ca se pot folosi descrieri diferite de la o firma la alta. S-au folosit doar doua fisiere la rulari, dar utilizatorul poate defini mai multe. c)Fisierul "fuzzy.inc" - utilizat de sistemul fuzzy SF2 de calcul al incrementului fuzzy. Contine regulile si variabilele si functiile de apartenenta aplicate la calculul incrementului fuzzy. S-a presupus ca este acelasi pentru toate firmele, dar se poate usor face o generalizare, prin introducerea mai multor descrieri.
Fisier de iesire:
Dupa rulare fisierul de output "firm.out" contine pe mai multe coloane preturile si beneficiile obtinute de fiecare firma la fiecare moment de timp (ciclu de iteratie). Numarul de linii este dat de numarul de pasi de iteratie. Analiza acestor valori permite determinarea duratei regimului tranzitoriu si modul in care s-a realizat stabilizarea preturilor.
Facilitati model:
- Flexibilitate mare datorata fisierelor de configurare. Utilizatorul poate simula diferite modele prin modificarea fisierelor de configurare (se pot schimba variabilele fuzzy de intrare si iesire, regulile de inferenta fuzzy etc.). Pentru generarea automata a fisierului de configurare "firm.in" a fost dezvolat un instrument gen_firm.exe
- Posibilitatea folosirii mai multor tipuri de operatori fuzzy, nu numai cei clasici (in sens Mamdani) "AND"-min si "OR"-max, respectiv a tipului de implicatie fuzzy. Se modifica in codul sursa variabilele corespunzatoare si se recompileaza aplicatia.
- Utilizatorul poate defini orice graf care sa descrie conexiunile dintre firmele incluse in modelul economic (diverse topologii), prin matricea de intarzieri din fisierul "firm.in". Prin zerorificarea valorilor se indica nonexistenta unei conexiuni intre doua noduri ale grafului (firme). Functie de valorile intarzierilor se pot delimita arii de influenta locale
- Pentru optimizarea timpilor de rulare a fost dezvoltat un planificator de sarcini care stabileste ordinea de distribuire a task-urilor la nodurile de calcul de catre nodul central, functie de timpii de rulare estimati pentru calculul beneficiului fiecarei firme
Recomandari:
Se recomanda utilizarea modelor pentru studiul dinamicii neliniare a sistemelor in bucla de decizie. Numarul de firme poate fi cateva sute;pentru numarul de pasi de iteratie nu exista o limitare. in simulari s-a constatat o stabilizare a sistemului dupa 200-300 de pasi. Pentru interpretarea datelor de iesire a fost conceput separat un instrument care determina durata regimului tranzitoriu si tipul de stabilizare a sistemului.
b) Specificatiile serviciului grid pentru modelarea 3D a suprafetelor de teren in scopul simularii unor procese geo-fizice
Scopul serviciului: Serviciul grid AppGen3D_Server este un sistem distribuit destinat modelarii 3D a suprafetelor de teren, cu aplicabilitate in aplicatii de tip Sistem de Informatii Geografice. Modelul 3D este necesar pentru a putea realiza simularea unor procese geo-fizice ce ar putea pune in pericol siguranta teritoriului, si permite identificarea masurilor necesare pentru a realiza un sistem de protectie impotriva dezastrelor naturale.
Serviciul este destinat procesarii rapide a modelelor si permite procesarea modelelor de dimensiuni foarte mari, care nu pot fi procesate secvential.
Structura serviciului: Modelarea 3D consta in realizarea unei descrieri a suprafetei prin triunghiuri 3D, pornind de la o descriere prin puncte, linii sau poligoane. Pentru transmiterea datelor sunt utilizate fisiere de tip "shape" care reprezinta unul dintre standardele utilizate de Sistemele de Informatii Geografice.
Serviciul AppGen3D realizeaza modelarea suprafetelor de teren 3D prin divizarea domeniului, in functie de parametrii specificati de utilizator:
- in prima etapa, domeniul este divizat (procesul master) in functie de:
- numarul minim de puncte pentru care un subdomeniu este candidat la divizare,
- numarul maxim de procesoare disponibile.
- subdomeniile sunt procesate secvential (procesele slave). in aceasta etapa sunt generate modelele 3D ale subdomeniilor folosind un algoritm de triunghiularizare de tip Delaunay.
- modelele generate de procesele slave sunt unificate (procesul master). in aceasta etapa este generata si suprafata corespunzatoare spatiului dintre subdomenii (suprafata reprezentata de diferenta intre infasuratoarea convexa a multimii de puncte de intrare si infasuratoarele convexe ale punctelor din fiecare subdomeniu).
Conditii de utilizare: Serviciul a fost testat pe seturi de 500.000 puncte de descriere, pentru care procesarea dureaza cu aproximatie 12 minute, pentru divizarea domeniilor mai mari de 10.000 puncte, fara limitarea numarului de subdomenii generate. Timpul necesar procesarii depinde insa de distributia punctelor de descriere. Pentru o distributie uniforma a acestora se obtine o incarcare optima a procesoarelor si un timp de executie mai scurt.
Mod de apelare:Transmiterea informatiilor necesare procesarii se face prin intermediul unui fisier de comanda a carui cale completa este trimisa ca parametru in linia de comanda. Toate informatiile necesare serviciului sunt incluse in acest fisier de comanda. Rezultatul procesarii este transmis utilizatorului prin intermediul codului de retur si al fisierelor de iesire al caror nume complet a fost comunicat prin intermediul fisierului de comanda:
Recomandari: Serviciul este destinat utilizarii de catre aplicatiile de tip SIG. Pentru vizualizarea rezultatelor procesarii a fost proiectata si implementata o aplicatie de vizualizare 3D, folosind biblioteca OpenGL. Codul realizat este portabil, aplicatia poate fi compilata pentru sistemele de operare Windows si Linux (GTK).
4. Diseminarea informatiilor
Au fost organizate manifestari stiintifice si mese rotunde in cadrul carora au fost prezentate rezultatele activitati de cercetare desfasurate in cadru proiectului GRAI. Astfel, conducatorul de proiect a organizat workshop-ul SE-EGRID (Workshop on Scientific and Educational Grid Applications) in cadrul Simpozionului international SACCS 2007 ( 9th International Symposium on Automatic Control and Computer Science, Iasi, Romania, November 16-18, 2007), coordonatori: Mitica Craus si Horia-Nicolai Teodorescu, http://www.saccs07.tuiasi.ro/workshop.htm. (Doua lucrari din cadrul acestui workshop se afla sub tipar in Memoriile Sectiilor Academiei Romane).
De asemenea, conducatorul de proiect impreuna cu partenerul AR-IIT au organizat simpozionul "Grid Applications", coordonatori Horia-Nicolai Teodorescu si Mitica Craus, http://www.iit.tuiasi.ro/ecit2008/.
Prof.dr.ing. Horia-Nicolae Teodorescu impreuna cu prof.dr. Mitica Craus au organizat o sesiune invita "Grid and Advanced Computing in Applications", in cadrul conferintei CSCS16, 16th International Conference on Control Systems and Computer Science, Mai 22-25, 2007, Universitatea Politehnica, Bucuresti. In urma invitatiei primite din partea ICIA Bucuresti, un grup de specialisti de la Institutul de Informatica Teoretica au co-organizat si participat la seminarul de cercetare "Actualitati in domeniile calculului paralel si distribuit, Procesarea limbajului natural si Tehnologia vorbirii si inferentele intre domenii" Institutul de Informatica Teoretica - Institutul de Cercetare in Inteligenta Artificiala - ICIA - (institute ale Academiei Romane) - 25- 26 aug. 2008, Bucuresti (la sediul Academiei Romane).
Modelele si produsele software dezvoltate in cadrul proiectului de cercetare au fost prezentate studentilor din anii terminali, masteranzilor si doctoranzilor de la facultatile implicate in proiect. Acestia au utilizat modelele si implementarile acestora in procesul de realizare a proiectelor de diploma, a lucrarilor de disertatie, tezelor de doctorat.
Documentarea realizata in cadrul proiectului a contribuit la actualizarea continuturilor cursurilor sustinute de membrii echipelor de cercetare. Rezultatele teoretice si practice de valoare stiintifica au fost publicate in reviste si proceedings-uri. in perioada 2006-2008, membrii echipelor de cercetare partenere in proiectul GRAI au publicat 7 carti, 34 articole stiintifice in reviste (20 in reviste din tara si 14 in reviste din strainatate) si 99 lucrari in proceedings-uri (58 in tara si 41 in strainatate). Mentionam ca o parte din lucrari au fost elaborate doar partial in legatura cu acest proiect.
Concluzii
Prin domeniile abordate si prin obiectivele stabilite, proiectul vizeaza directii noi ale cercetarii stiintifice, contine provocari si idei inovative. Membrii consortiului au avut si vor avea posibilitatea sa-si largeasca orizontul cunoasterii stiintifice in domenii de varf ale tehnologiei informatiei si comunicatiilor. Au fost puse bazele unui centru de excelenta intr-un domeniu multi-disciplinar, cum este cel al proiectului. De asemenea, tinerii au avut si au in continuare sansa de afirmare pe plan national si international prin diseminarea rezultatelor muncii lor. Experienta acumulata in cursul derularii acestui proiect va putea fi folosita pentru dezvoltarea de noi nuclee grid in comunitatea romaneasca, pregatind astfel integrarea in platforme europene de acest tip. Membrii echipelor de cercetare au desfasurat o ampla si consistenta activitate de cercetare si documentare. Pentru aceasta au fost folosite resursele bibliotecilor celor 4 universitati implicate in proiect, biblioteca Academiei Romane - Filiala Iasi, biblioteci on-line si alte surse de documentare disponibile pe Web. Echipele de cercetare au fost in contact permanent, au colaborat la culegerea datelor, au participat la discutii pe temele abordate in proiect. Pentru implementarea si testarea serviciilor si aplicatiilor grid au fost utilizate resursele de calcul disponibile in laboratoarele partenerilor acestui proiect. Partenerii au colaborat pentru asigurarea suportului de testare pentru toate echipele de cercetare. Rezultatele obtinute demonstreaza viabilitatea proiectului GRAI. Reteaua de calculatoare suport pentru gridul GRAI este functionala. Prin serviciile si aplicatiile grid realizate a fost construita o platforma de calcul de mare putere si amploare. Noutatea si importanta proiectului au permis autorilor sa publice rezultatele de valoare in reviste de impact, sa participe cu lucrari la conferinte, simpozioane, workshop-uri internationale importante in domeniu.
Dificultati, aspecte neasteptate si particularitati ale cercetarii
Nu au existat dificultati majore in cadrul acestui contract. Principalele dificultati au fost legate de furnizori, care nu au raspuns intotdeauna la asteptarile noastre. O dificultate asteptata a fost legata de aspectele de corelare intre parteneri, care au necesitat mult timp de intalniri si discutii privind corelarea activitatilor, dar asemenea aspecte fusesera prevazute. Au existat dificultati de documentare privind ultimele evolutii in domeniu, dar aceste dificultati au fost surmontate inclusiv prin schimb de materiale intre parteneri. Printre surprizele placute se numara reusita dezvoltarii de modele teoretice noi, simultan cu realizarea de aplicatii. Practic toti partenerii au avut, in diverse faze, rezultate de interes teoretic in modelare si la nivelul instrumentarului matematic-informatic. Nu ne asteptam nici la un numar atat de mare de publicatii.
In concluzie, consideram contractul ca fiind unul de succes. |
